
DePin ,是 Decentralized Physical Infrastructure Networks(中心化物理基础设施网络) 的简称。DePin 概念核心在于利用代币激励用户部署硬件设备,以提供真实世界的商品与服务或数字资源例如算力、存储和网络带宽等。据 Messrai 报道,目前整个赛道估值大概在 90 亿美金左右,到 2028 年有望增长到 3.5 万亿美金的规模。
目前符合 DePin 概念的项目也有不少,其中主打分布式 AI 算力调度的 UtilityNet(以下简称 Utility)经过一年来的发展,在近期刚刚推出基于 TPU(AI 专用加速芯片)和相关智算服务器构建的 AI 容器云测试平台。感兴趣的 AI 开发者通过 Utility 官方 Twitter 账号公布的邮件地址,可以申请参与 Utility AI 容器云的测试,以此获得一定的 AI 云算力进行大模型的部署和推理。这些云算力背后的芯片和设备都是由参与目前封闭测试期的 Utility 矿工提供的。
Utility 创新的提出了一个全新的 Proof Of ComputationIntegrity(简称 POCI,中文翻译为“可信计算”)共识机制,通过 AI 专用芯片内部的安全引擎模块,结合链上的加密学原理,让芯片能够自我证明,从而达到不损耗算力就可以获得激励的目的。因为过去流行的 POW 共识把设备算力在挖矿过程中都已经消耗殆尽了,这显然跟 DePin 理念是冲突的,算力被挖矿消耗掉,就无法流转给真正的需求方。因此,Utility 这套创新 POCI 共识为其 Token 真正的实现算力从矿工到租用者之间的流转提供了现实的解决方案。
作为一名 AI 开发者,已关注 Utility 这个项目一段时间,在通过官方通道申请并试用了测试版的 Utility AI 容器云之后,为大家分享一下相关的试用报告。
基于 Utility 去中心化的挖矿激励原理,Utility AI 容器云的使用界面设计了矿工管理端与芯片用户端,区分不同的用户与操作逻辑,使得 Utility AI 容器云平台中不同类型的用户可以出色地协调配合,以完成算力从矿工到算力租用者之间的流转。
一、 Utility AI 容器云矿工管理端
1.矿工管理端说明
Utility AI 容器云矿工管理端具有独立的访问入口页面,当前测试版访问地址为https://cloud.utlab.io/admin/#/,登录页面如下:

2.平台监控
Utility AI 容器云的监控架构为 NodeExporter+Prometheus+Grafana,面向对象为集群监控和训练任务监控,以 Grafana 网页的形式展示。NodeExporter 可以收集到节点的各种资源信息,使用情况,并且以 prometheus 支持的数据格式存储与本地文件。Prometheus 以 Pull 的形式,将每个节点的 NodeExporter 服务的本地数据收集汇聚到其中心数据库。Grafana 网页前端服务启动前配置好 Prometheus 的数据库 API 调用路径,定时请求 Prometheus 的数据指标,就可向矿工动态地展示集群和平台中所有 AI 芯片用户正在运行的任务的指标数据的图表。
集群监控
集群监控以 Grafana 网页的形式内嵌于管理端网页内。
如下图,【登录管理网络端/集群监控】展示了集群信息:

3.资源管理
Utility AI 容器云矿工管理端支持对平台硬件资源进行便捷管理。平台资源管理模块可以分为服务器节点、系统资源、自定义资源、资源规格、资源池。
节点
节点即服务器,平台底层集群系统在启动的时候会自动发现已经组成集群的服务器,发现其各种属性。如 IP、Hostname、所赋予的标签、是否 Ready 的状态、拥有何种资源等详情信息。
如下图,【登录矿工管理端/资源管理/节点】展示了系统自动发现的节点列表:

资源
从物理上看,所有资源都组装于服务器节点,并由平台系统自动发现,即是系统资源。系统资源有各种名字,各种区分形式,它可以根据各种逻辑划分。
如下图,【登录矿工管理端/资源管理/资源】展示了自动发现的系统资源列表:

为了方便管理、友好展示、感性利用,平台设计了自定义资源功能,矿工可根据不同的逻辑将已有的系统资源重新定义为一种新的自定义资源。
如下图,【登录矿工管理端/资源管理/资源/自定义资源】可根据系统资源增加自定义资源--TPU 1684 或者 TPU 1684 X(1684 系列是 AI 芯片名称):

资源规格
为了更好地向用户展示平台所拥有的资源还有更好地统计用户使用资源的情况。平台将服务器上组装的不同种类的资源归为一个组,这种将资源归为组的功能即是资源规格。管理员定义好资源规格的名字,用户就可感性地从资源规格名字中获取资源的信息,选择自己想要的资源组用于运行自己的任务。
如下图,【登录管理网页端/资源管理/资源规格】可根据所有资源创建资源规格(4 CPU-2 GB-2 TPU 1684):

资源池
资源池用于隔离集群的服务器资源。纵向看,资源以服务器节点为粒度。横向看,资源又以资源规格为粒度。服务器节点面向管理员,资源规格面向用户。自然地,如果要更好地将资源与用户解耦与隔离,需要一个资源池的概念。资源池将资源逻辑地重新分割,Utility AI 容器云以服务器节点为粒度,将资源以服务器节点的形式整体划分到不同的资源池,不同的资源池可以绑定到用户群组。以这样的形式,可以很好地将集群的资源隔离,不同的资源可分配给不同的用户群。
如下图,【登录矿工管理端/资源管理/资源池】系统自带的默认资源池初始化包含所有资源节点,也可根据不同业务逻辑点击按钮创建新的资源池:

矿工管理端支持对平台硬件资源进行便捷管理。平台资源管理模块可以分为服务器节点、系统资源、自定义资源、资源规格、资源池。
4.机时管理
矿工可以根据 UNC/机时的价格设定租用各种 AI 芯片费用,当算力租赁用户购买了芯片租用订单,AI 芯片容器任务启动时间开始,平台会扣取相应的机时。平台按照资源规格设置单价 UNC/机时,计费规则如下:
AI 芯片容器任务机时 = 子任务 1 机时 + 子任务 2 小时 + ... + 子任务 n 机时
子任务机时 = 副本 1 机时 + 副本 2 机时+ ... + 副本 n 机时
副本机时 = 资源规格 * (副本运行终止时间 - 副本运行起始时间)
机时管理包括机时列表,充值记录和消费记录
用户机时列表

二、 AI 容器云芯片用户端
1. 用户使用说明
Utility AI 容器云芯片用户端的访问地址为https://console.utlab.io/utnetai/,登录页面如下:

2. 概览
概览页用于展示不同状态的训练任务的个数信息,剩余机时信息,消费及充值记录信息,同时向用户提供快速创建 Jupyter notebook,算法,训练任务,任务模板,算法,数据集,镜像功能。

3. 模型开发
Jupyter notebook 管理
Jupyter notebook 管理提供在线编程环境,用来调试、运行和保存算法以支撑后续的模型训练。该模块支持开源的 JupterLab,用户需要提前制作包含 Jupyterlab 程序的镜像。用户可以创建、打开、启动、停止、删除 notebook,用户在 JupterLab 里编辑算法将会自动保存

创建 notebook
点击创建按钮,选择相应算法、镜像、数据集(可选)和资源,可在「高级设置」中选择任务数,点击确定创建 notebook。

打开 notebook
点击打开按钮,弹出悬浮窗,选择对应子任务,打开 notebook


本次尝试部署 ONNX 模型,该模型从清华 GLM-6 B 转换而来,相关推理在 Nvidia Tesla A 100 40 G 上部署成功,现尝试在申请到的官方给到 4 CPU 2 G + 1 颗 1684 x 芯片的 infer 容器环境推理,如下图

之后上传好模型经过编译后目录已经确定,尝试在 notebook 中打开,并成功加载目录和控制台,不得不说在该容器中的体验和传统 AI 工程师工作流几乎吻合,可以见得该容器云专业性和投入,这里要给 UtilityNet 团队点个赞,兼容 Jupiter 的全套环境对于需要 plot 监控和专业输出的开发者实在太友好了。在 notebook 中,可以看到目录中相关加载如图

接下来进入容器控制台,体验几乎完美,可能因为申请试用的服务器集群在亚洲的原因,所以延时基本和之前采购的 AWS 香港服务器差不多。因为编译好的缘故,我们直接用 Pytho n3运行,dev 0 就是分配到的那张 SC 7 三芯 BM 1684 X 卡中属于我的第一颗芯片,通过命令指定并运行,短暂延时后成功推理,因此单卡可以并行三个 ChatGLM,通过分发到三个用户提供并行体验,让我们对 BM 1684 x 在 UtilityNet 的广泛场景充满期待,相关测试可以参考下图

停止 notebook
最后,点击停止按钮,停止 notebook,结束体验和机时。

三、总结
通过全流程体验,从申请容器,到分配到2C PU 4 G 单芯 1684 x 容器,到部署编译在 infer 环境中,到 notebook 便捷展开 Jupiter,到控制台文件目录和 GLM 的成功推理,整个流程无比丝滑,对相关 AI 开发者和算力使用者非常友好。不得不对如此强大的容器云未来能够开源和一键部署在 UtilityNet 的算力提供商节点充满无限期待,对官方明年 2-3 月份的公开测试网和分布式算力的未来也更加肯定了信心。
此文由 比特币官网 编辑,未经允许不得转载!:首页 > 比特币新闻 » DePin赛道的落地应用展示:Utility AI容器云使用报告
 链上数据解读:比特币高位瀑布,是牛市调整还是周期转变?
链上数据解读:比特币高位瀑布,是牛市调整还是周期转变? 比特币和Nadaq之间的40天相关性目前为零
比特币和Nadaq之间的40天相关性目前为零 Outlier Bitcoin Base Camp加速器九家入选加密初创公司速览
Outlier Bitcoin Base Camp加速器九家入选加密初创公司速览 种子轮融资 2700 万美元 创始人亲述Avail“三位一体”解决方案和愿景
种子轮融资 2700 万美元 创始人亲述Avail“三位一体”解决方案和愿景 总统初选接连获胜,「特朗普主题」加密资产收益如何?
总统初选接连获胜,「特朗普主题」加密资产收益如何? 华尔街疯狂抢购比特币
华尔街疯狂抢购比特币 由花旗前高管创立的公司计划提供比特币存托凭证
由花旗前高管创立的公司计划提供比特币存托凭证 项目周刊 | 比特币现货ETF以3比2投票通过 现货以太坊ETF今年获批可能性为70%
项目周刊 | 比特币现货ETF以3比2投票通过 现货以太坊ETF今年获批可能性为70%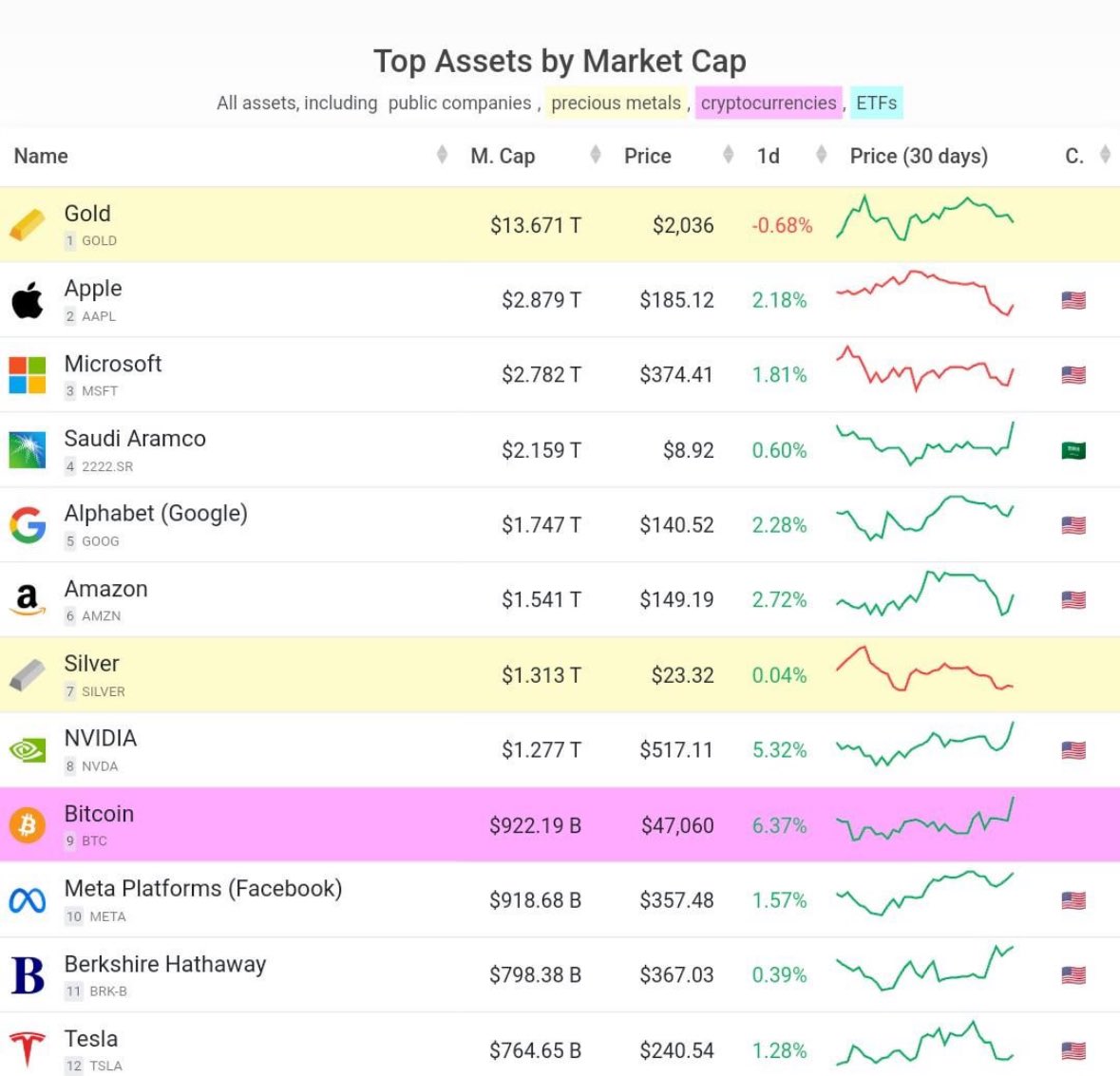 比特币超越Meta成为全球市值第九大资产
比特币超越Meta成为全球市值第九大资产 比特币突然暴拉:跻身1万亿
比特币突然暴拉:跻身1万亿 一周融资速递 | 15家项目获投,已披露融资总额约530万美元(1.8-1.14)
一周融资速递 | 15家项目获投,已披露融资总额约530万美元(1.8-1.14) 新总统Javier Milei将如何应对加密货币?阿根廷加密税与前瞻
新总统Javier Milei将如何应对加密货币?阿根廷加密税与前瞻